ElasticSearch Geo
General Flow - Geo Distance
Given any geo point and find the closest US cities.
# create an index mapping
curl -XPUT http://localhost:9200/us_large_cities -d '
{
"mappings": {
"city": {
"properties": {
"city": {"type": "string"},
"state": {"type": "string"},
"location": {"type": "geo_point"}
}
}
}
}
'
# index (download full list from: http://www.elasticsearchtutorial.com/downloads/insert_big_cities.sh)
curl -XPOST http://localhost:9200/us_large_cities/city/ -d '{"city": "Anchorage", "state": "AK","location": {"lat": "61.2180556", "lon": "-149.9002778"}}'
curl -XPOST http://localhost:9200/us_large_cities/city/ -d '{"city": "Birmingham", "state": "AL","location": {"lat": "33.5206608", "lon": "-86.8024900"}}'
curl -XPOST http://localhost:9200/us_large_cities/city/ -d '{"city": "Huntsville", "state": "AL","location": {"lat": "34.7303688", "lon": "-86.5861037"}}'
curl -XPOST http://localhost:9200/us_large_cities/city/ -d '{"city": "Mobile", "state": "AL","location": {"lat": "30.6943566", "lon": "-88.0430541"}}'
curl -XGET 'http://localhost:9200/us_large_cities/city/_search?pretty=true' -d '
{
"query": {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"geo_distance" : {
"distance" : "20km",
"location" : {
"lat" : 37.9174,
"lon" : -122.3050
}
}
}
}
}
}'
# The previous you get the hits without distance. Below you can get the distance out.
curl -XGET 'http://localhost:9200/us_large_cities/city/_search?pretty=true' -d '
{
"sort" : [
{
"_geo_distance" : {
"location" : {
"lat" : 37.9174,
"lon" : -122.3050
},
"order" : "asc",
"unit" : "km"
}
}
],
"query": {
"filtered" : {
"query" : {
"match_all" : {}
},
"filter" : {
"geo_distance" : {
"distance" : "20km",
"location" : {
"lat" : 37.9174,
"lon" : -122.3050
}
}
}
}
}
}'
Q1) How they calculate the distance between 2 geopoints?
- arc
- plane
- sloppy_arc
NOTE: see the note below for more detail.
Q2) What URL in Google map connects 2 geopoints?
Q3) What is memory size used per geopoint?
- Each lat/lon pair requires 16 bytes of memory.
- You can reduce this memory requirement by switching to a compressed fielddata format and by specifying how precise you need your geo-points to be.
- You can avoid using memory altogether via:
- use doc_values OR
- use optimizing bounding box
# this setting on mapping will reduce lat/lon to 4 bytes instead of 16 as default.
"location": {
"type": "geo_point",
"fielddata" : {
"format": "compressed",
"precision": 1km
}
}
# this setting will avoid the heap altogether as it will tell ES no loading geo-pointed into memory but instead stored on disk.
"location": {
"type": "geo_point",
"doc_values": true
}
# to use geo_bounding_box filter effectively, you need to set lat_lon index to true.
"location": {
"type": "geo_point",
"lat_lon": true
}
Q4) How to combine spatial search with full-text search, structured search and analytics?
- Show me restaurants that mention vitello tonnato, are within a 5-minute walk, and are open at 11 p.m., and then rank them by a combination of user rating, distance, and price.
- Show me a map of vacation rental properties available in August throughout the city, and calculate the average price per zone.
Q5) What are the ways of representing geolocations?
- geo_point : lat/lon
- geo_shape : GeoJSON (pure for filtering and decide if 2 shapes overlap etc.
Once you set a field as geo_point type, you can set its lat/lon thru these ways:
# single string
"location": "40.715, -74.011"
# 2 separate fields
"location": {
"lat": 40.722,
"lon": -73.989
}
# array (they are long, lat in order but not common order we used)
"location": [ -73.983, 40.719 ]
Q6) What are the 4 ways for geo-points filtering?
- geo_bounding_box
- specify top_left and bottom_right coordinate of the rectangle
- It is the one geo-filter that doesn't require all geo-points to be loaded into memory. Because all it has to do is check whether lat and lon values fall within the specified ranges and it can use inverted index to do a range filter. To achieve that, you need to set "lat_lon: true" in mapping and put "type: indexed" in query filter. That way ES will index location.lat and location.lon separately and these field can be used for searching without loading up the documents.
GET /attractions/restaurant/_search
{
"query": {
"filtered": {
"filter": {
"geo_bounding_box": {
"type": "indexed",
"location": {
"top_left": {
"lat": 40.8,
"lon": -74.0
},
"bottom_right": {
"lat": 40.7,
"lon": -73.0
}
}
}
}
}
}
}
- geo_distance
- A geo-distance calculation is expensive. To optimize performance, Elasticsearch draws a box around the circle and first uses the less expensive bounding-box calculation to exclude as many documents as it can. It runs the geo-distance calculation on only those points that fall within the bounding box.
- You can also tune it via using less costy distance algorithms. There are arc, plane (ie. fastest but less accurate as it treats the world as flat), sloppy_arc (ie. Haversine formula that is 4-5x faster than arc with 99.9% accuracy). sloppy_arc is used as default.
GET /attractions/restaurant/_search
{
"query": {
"filtered": {
"filter": {
"geo_distance": {
"distance": "1km",
"distance_type": "plane",
"location": {
"lat": 40.715,
"lon": -73.988
}
}
}
}
}
}
- geo_distance_range
- The only difference between the geo_distance and geo_distance_range filters is that the latter has a doughnut shape and excludes documents within the central hole.
GET /attractions/restaurant/_search
{
"query": {
"filtered": {
"filter": {
"geo_distance_range": {
"gte": "1km",
"lt": "2km",
"location": {
"lat": 40.715,
"lon": -73.988
}
}
}
}
}
}
- geo_polygon
By default, all of these filters work in a similar way: the lat/lon values are loaded into memory for all documents in the index, not just the documents that match the query (ie. fielddata). Each filter performs a slightly different calculation to check whether a points falls into the containing area. As you can see, geo-filters are expensive. Three approaches you could may want to consider:
- So, you better use a filter like term, range to cut out the documents first before feeding them to the filter.
- If you don't want to use the heap for this, set doc_values: true.
- Cache the geo-filter if it is going to be reused many times. Like boundng box filter for New York. You can make it as filtered set before NY user-based filter.
"geo_bounding_box": {
"type": "indexed",
"_cache": true,
"location": {
...
Spatial Indexing
QuadTree
- Tree with 4 children and has leaf node a boundary box that holds a set of geopoints.
- Inserting data into a quadtree is simple: Starting at the root, determine which quadrant your point occupies. Recurse to that node and repeat, until you find a leaf node. Then, add your point to that node's list of points. If the list exceeds some pre-determined maximum number of elements, split the node, and move the points into the correct subnodes.

A representation of how a quadtree is structured internally.
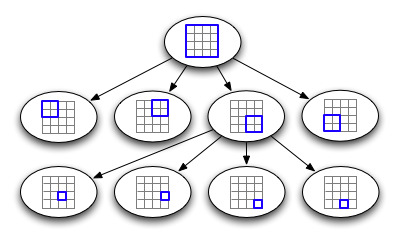
- To query a quadtree, starting at the root, examine each child node, and check if it intersects the area being queried for. If it does, recurse into that child node. Whenever you encounter a leaf node, examine each entry to see if it intersects with the query area, and return it if it does.
- Effectively a quadtree is a trie b/c the values of the tree nodes do not depend on the data being inserted.
GeoHash
- Read this link to learn about how to compute geohash: http://www.bigfastblog.com/geohash-intro
Hilbert Curve
Geohash-based grouping
A geo hash is a representation of a coordinate that interleaves the bit representations of the latitude and longitude and base32 encodes the result. (missing A, L, O as they don't want them to confuse with the number).
aggregation by geohash
curl -XPOST "http://localhost:9200/conferences/_search" -d'
{
"aggregations" : {
"conference-hashes" : {
"terms" : {
"field" : "conference.coordinates.geohash"
}
}
}
}'
# result with one character added per drill
[...]
"aggregations": {
"conference-hashes": {
"buckets": [
{
"key": "u",
"doc_count": 2
},
{
"key": "u0",
"doc_count": 2
},
{
"key": "u0w",
"doc_count": 1
},
[...]
}
}
Apply geohash grouping after the geo point filter. For each group, calculate the centroid (but you need to enable the dynamic scripting).
geohash_grid
- precision: 1-12 (Default is 5) in length. Most granular can reach less than 1 square metre of land.
- the specified field must be of type geo_point to be used.
- without doing anything on top, the result will give you a list of buckets (key, doc_count).
- size: # of buckets to return (default 10,000). 0=all
- shard_size: default is max(10, (size x # of shards)). 0=all
{
"query": {
"match_all": {}
},
"size": 0, "aggs": {
"filtered_cells": {
"filter": {
"geo_bounding_box": {
"location": {
"top_left": "50.1234, 4.0000",
"bottom_right": "52.1234, 4.5555"
}
}
},
"aggs": {
"cells": {
"geohash_grid": {
"field": "location",
"precision": 3
}
}
"aggs": {
"center_lat": {
"avg": {
"script": "doc['location'].lat"
}
},
"center_lon": {
"avg": {
"script": "doc['location'].lon"
}
}
}
}
}
}
}
Spatial Data
- Open Street Map and extract data using this python script
- GeoName - 8 millions geo points
- Census and Housing Data in Australia
Reference
- https://mapbutcher.gitbooks.io/using-spatial-data-in-elasticsearch/content/aggregation/README.html
- https://www.elastic.co/blog/geo-location-and-search
- https://github.com/jillesvangurp/geogeometry/blob/master/src/main/java/com/jillesvangurp/geo/GeoGeometry.java#L697
- http://blog.notdot.net/2009/11/Damn-Cool-Algorithms-Spatial-indexing-with-Quadtrees-and-Hilbert-Curves
- https://www.factual.com/blog/how-geohashes-work
- http://blog.florian-hopf.de/2014/08/use-cases-for-elasticsearch-geospatial.html
- https://github.com/perrygeo/spatial-search-showdown (look like postgresql is 10x faster than elasticsearch for spatial search).
- JTS Topology - an API of spatial predicates and functions for processing geometry